
Vuoi saperne di più sulla sintesi vocale text-to-speech? Ecco le risposte a 11 domande comuni. Qui, inoltre, troverai moltissime informazioni su come utilizzare in modo efficace la sintesi vocale text- to-speech nell’ambito dell’istruzione per supportare, attirare e trattenere gli studenti.
Con l’avvento della tecnologia educativa, il panorama dell’apprendimento sta vivendo una fase di rapida evoluzione. Ci sono sempre più modi per fruire dei contenuti dei corsi, e le aspettative di studenti e insegnanti sul modo in cui gli educatori forniscono tali contenuti sono più alte che mai.
Con la disponibilità di diversi strumenti tecnologici che mettono tutti nelle stesse condizioni e consentono agli studenti di apprendere in molti modi diversi, i responsabili delle organizzazioni, i progettisti dei corsi e gli insegnanti devono essere consapevoli delle diverse forme di contenuto disponibili, tra cui la sintesi vocale text- to-speech (TTS) che “legge” in modo digitale, a voce alta, i contenuti scritti.
Nel contesto di questa rivoluzione tecnologica nel campo dell’istruzione l’audio è un segmento importante e in crescita; le istituzioni più attente sanno come sfruttare questo potente mezzo di comunicazione.
Noi di ReadSpeaker siamo degli specialisti nel settore della sintesi vocale text-to-speech. Capiamo perché e come implementare l’audio nei corsi. Qual è il nostro obiettivo? Aiutare le istituzioni educative a comprendere e utilizzare l’audio nel contesto della loro offerta formativa. Per perseguire questi obiettivi abbiamo stilato un elenco di domande che ci vengono poste dalle istituzioni in merito alla sintesi vocale text-to-speech e ai contenuti audio per l’istruzione. E ora passiamo alla parte più importante: diamo delle risposte a queste domande.
Hear for yourself!
Request a demo
1. Nel campo delle tecnologie educative gli acronimi abbondano. Che cosa significa l’acronimo TTS?
La sintesi vocale text-to-speech, o TTS per brevità, permette di convertire il testo in emissione vocale. Da non confondere con i sistemi speech-to-text, che convertono gli input vocali in output scritti, i sistemi di sintesi vocale text-to-speech offrono una voce generata dal computer che “legge” ad alta voce il testo all’utente.
I sistemi di sintesi vocale text-to-speech attualmente disponibili funzionano su cloud, sono integrati in server o anche solo sui dispositivi. A seconda del motore di sintesi vocale text- to-speech (TTS) – il software che genera il parlato sintetico – questi sistemi sono compatibili con qualsiasi formato di testo digitale, comprese le scansioni di documenti stampati. Tutto questo porta a un livello di assistenza educativa estremamente elevato per gli studenti con problemi di vista. La sintesi vocale text-to-speech supporta i lettori con difficoltà durante l’apprendimento. Si tratta, inoltre, di uno strumento essenziale per gli studenti che si avvicinano allo studio di una seconda lingua e che hanno bisogno di assimilare espressioni scritte e parlate in una nuova lingua.
La sintesi vocale text-to-speech non è tuttavia semplicemente una tecnologia assistiva, bensì una tecnologia educativa completa. Come ribadiremo più avanti nel corso di queste FAQ, la sintesi vocale text-to-speech offre vantaggi di apprendimento a tutti gli studenti, indipendentemente dalle circostanze del singolo. La sintesi vocale text-to-speech consente agli adulti impegnati di studiare tenendo libere le mani mentre, ad esempio, preparano la cena. Per gli studenti che frequentano corsi on-line offre un sollievo dall’affaticamento causato dalle molte ore trascorse davanti a uno schermo. La sintesi vocale text-to-speech offre – in primis – la possibilità di scegliere, consentendo ai singoli studenti di personalizzare l’esperienza formativa in base alle proprie esigenze e preferenze.
2. La sintesi vocale text-to-speech non si limita alla fornitura di file audio?
Certo, i motori di sintesi vocale text-to-speech permettono di creare file audio scaricabili con contenuti testuali parlati, di norma nell’oramai diffusissimo formato MP3. Ma non finisce qui. Le tecnologie di sintesi vocale text-to-speech offrono anche funzionalità di riproduzione immediata tramite un’app, un browser o ancora avvalendosi di un sistema di gestione dell’apprendimento (LMS – learning management system).
Ma spingiamoci un passo oltre: molti strumenti di sintesi vocale text-to-speech offrono anche una funzionalità di “presentazione bi-modale” che integra l’evidenziazione del testo come accompagnamento. In questo modo gli studenti potranno leggere il testo evidenziato mentre ne ascoltano il contenuto. È possibile integrare la sintesi vocale text-to-speech anche in altri modi, per consentire – ad esempio – allo studente di ascoltare ciò che sta digitando nei documenti di testo o nei motori di ricerca. Molti strumenti vocali si servono della sintesi vocale text-to-speech per fornire funzionalità essenziali.
La tecnologia per l’istruzione di ReadSpeaker integra solide funzionalità di sintesi vocale text-to-speech con strumenti di apprendimento correlati: in questo modo gli studenti potranno personalizzare in prima persona la loro esperienza di fruizione dei testi. Il webReader, ad esempio, è uno strumento on-line basato su cloud di ReadSpeaker che consente agli studenti di ascoltare contenuti testuali in più di 50 lingue, scegliendo tra oltre 200 voci realistiche. Gli studenti potranno dunque ascoltare il testo parlato con un solo clic (o un tasto di scelta rapida) o scaricare un MP3 per la fruizione offline.
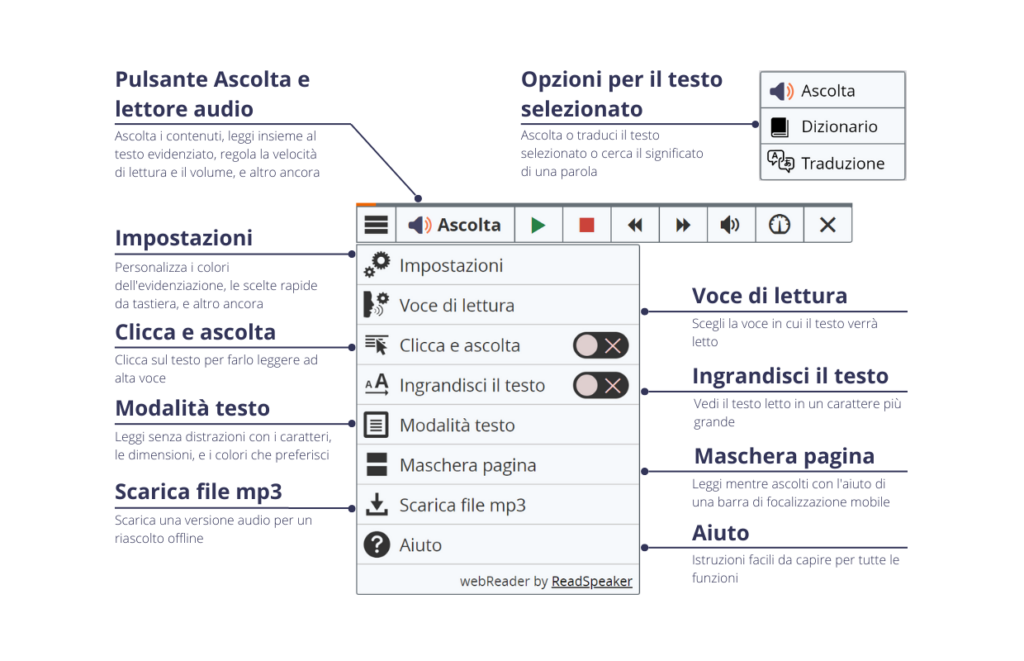
L’interfaccia utente di WebReader è disponibile su sistemi di gestione dell’apprendimento, siti web, applicazioni mobili e altro ancora.
Ma webReader rende prontamente disponibili diversi strumenti, tra cui:
- Sintesi vocale text-to-speech ed evidenziazione del testo simultanea – Lo strumento WebReader evidenzia ogni parola sullo schermo esattamente quando viene pronunciata, integrando così i contenuti visivi e audio con l’obiettivo ultimo di facilitare la comprensione.
- Ridimensionamento del testo – Ingrandire il testo sullo schermo sarà un gioco da ragazzi – bastano un clic o un tocco, con o senza l’ascolto del contenuto letto ad alta voce.
- Modalità solo testo – Elimina le immagini e altre distrazioni attivando la modalità solo testo, che mostra solo il contenuto testuale.
- Maschera pagina – Per i lettori in difficoltà spesso è utile utilizzare cartellini o righelli per concentrarsi su una singola riga alla volta. La funzionalità “Maschera pagina” digitale di WebReader porta questa capacità sullo schermo.
- Strumenti specifici per il testo – Evidenziare una riga di testo per richiamare un menu che consentirà di ascoltare il testo tramite la sintesi vocale text-to-speech, tradurre parole da una lingua all’altra o ancora cercare ulteriori informazioni sull’argomento del testo senza bisogno di aprire una nuova finestra del browser.
3. Che cos’è esattamente la presentazione bi-modale?
La presentazione bi-modale si riferisce semplicemente a informazioni che vengono presentate contemporaneamente in formato audio e visivo: leggere un testo, ascoltarlo e persino vedere parole (e/o frasi) evidenziate contestualmente alla progressione del testo.
Molti studenti ritengono che la presentazione bi-modale migliori la comprensione della lettura, la memorizzazione delle informazioni e la decodifica (il processo di abbinamento delle combinazioni di lettere ai suoni udibili). Questi benefici rafforzano la fiducia degli studenti creando al contempo una visione più positiva della lettura, gettando inoltre le basi per una vita di apprendimento.
La presentazione bi-modale dei contenuti si allinea anche con l’Universal Design for Learning (UDL), un quadro educativo raccomandato da politiche educative statunitensi come il National Education Technology Plan e da leggi quali l’Every Student Succeeds Act (ESSA). Tutto questo ci porta alla prossima domanda.
4. Che cos’è l’Universal Design for Learning?
L’Universal Design for Learning è un modo per dare a tutti gli studenti pari opportunità di apprendimento. Si tratta di una soluzione che predispone l’ambiente di apprendimento con strumenti e materiali flessibili per soddisfare al meglio le esigenze di ogni studente.
Quadro educativo e raccolta di raccomandazioni pratiche, l’UDL offre delle linee guida per l’apprendimento strutturate in tre categorie:
1. Coinvolgimento
Le linee guida dell’UDL consigliano di fornire agli studenti più modi per impegnarsi nelle esperienze educative, offrendo loro il massimo in termini di scelta e autonomia. In questo modo gli studenti rimangono motivati.
2. Rappresentazione
Ed è proprio qui che entra in gioco la presentazione bi-modale. Secondo l’UDL, gli educatori dovrebbero fornire molteplici mezzi per rendere possibile la fruizione dei contenuti del corso. Ciò include la possibilità di personalizzare il modo in cui vengono presentate le informazioni. Tutto questo aiuta gli studenti ad assorbire e trattenere le informazioni che l’insegnante sta cercando di veicolare.
3. Azione ed espressione
Offri agli studenti la possibilità di scegliere come completare le attività, con opzioni quali il movimento fisico, i supporti multipli e l’accesso alle tecnologie assistive.
La scelta dello studente è un tema ricorrente in tutte le linee guida UDL. Offrendo esperienze di apprendimento flessibili, ogni studente ha modo di trovare la strategia che più fa al caso suo. Dato che ogni studente è diverso dagli altri, queste strategie varieranno in modo significativo, ecco perché è necessaria una presentazione bi-modale oltre a strumenti di apprendimento digitale adeguati, come la sintesi vocale text-to-speech.
5. La sintesi vocale text-to-speech non è solo per i non vedenti o per chi ha difficoltà di apprendimento?
Quando la tecnologia di sintesi vocale text-to-speech ha iniziato la sua diffusione, gli educatori l’hanno utilizzata principalmente per aiutare gli studenti con difficoltà di apprendimento a superare le difficoltà di decodifica, per consentire loro di concentrarsi sul significato del testo scritto. Questa soluzione, inoltre, si è rivelata uno strumento decisamente utile anche per le persone con problemi di vista. E tutto questo è ancora vero.
La sintesi vocale text-to-speech, in effetti, è uno strumento potente per migliorare l’accessibilità digitale, che costituisce una preoccupazione di fondamentale importanza per gli educatori nell’era dell’apprendimento on-line. Le Linee guida per l’accessibilità dei contenuti web (WCAG – Web Content Accessibility Guidelines), un documento di portata internazionale, rappresentano lo standard di riferimento per la rimozione delle barriere di accesso per tutti gli utenti del web. Secondo il criterio di successo 3.1.5 delle linee guida WCAG, il testo deve risultare facile da leggere – al di sotto del livello di istruzione secondaria inferiore. In caso contrario è necessario fornire una versione del testo che non richieda elevate capacità di lettura. La sintesi vocale text-to-speech è il modo più semplice per rispettare questa regola WCAG (oltre a molte altre).
Ma torniamo alla domanda di partenza e diamo una risposta univoca: SÌ, la sintesi vocale text-to-speech va a beneficio degli studenti con disabilità ma anche degli studenti normodotati. Dato che gli studenti dei giorni nostri si sono abituati a svariati modi diversi di fruire dei contenuti, a seconda delle circostanze e delle esigenze, sempre più spesso la sintesi vocale text-to-speech e il supporto audio vengono utilizzati da tutti i tipi di studenti, a prescindere dalla loro situazione individuale: studio di una seconda lingua, elevata quantità di contenuti, multi-tasking o molti altri scenari individuali che gli studenti sperimentano.
6. In che modo l’ascolto aiuta gli studenti?
La sintesi vocale text-to-speech e la presentazione bi-modale sono aspetti dell’UDL che offrono una serie di modi flessibili per soddisfare le esigenze di una popolazione di studenti diversificata. In questo modo tutti gli studenti beneficiano delle stesse opportunità di apprendimento e di successo. Se da un lato è vero che la presentazione bi-modale viene usata da anni per le esigenze di accessibilità, i professionisti dell’apprendimento stanno ora riconoscendone i vantaggi per tutti gli studenti. Un numero considerevole di ricerche ha dato prova dell’efficacia dell’apprendimento bi-modale sul successo degli studenti. Secondo la ricerca, i vantaggi comprovati della presentazione bi-modale dei contenuti includono:
- Miglioramento della comprensione in fase di lettura
- Miglioramento del riconoscimento delle parole
- Miglioramento delle capacità di richiamo delle informazioni
- Decodifica facilitata
- Una visione più positiva della lettura
- Aumento del tempo di lettura
- Aumento della capacità di prestare attenzione e di ricordare le informazioni in fase di lettura
- Maggiore attenzione alla comprensione anziché alla decodifica delle parole
- Maggiore resistenza ai compiti di lettura
- Miglioramento del riconoscimento e della capacità di correggere gli errori nella scrittura dello studente
- Aiutare gli studenti con disabilità a mantenere il livello dei loro compagni in tutte le materie
- Miglioramento dell’autostima, della motivazione e della fiducia in se stessi
7. Esiste una base scientifica a supporto del ruolo della sintesi vocale TTS nel miglioramento dei risultati a livello di apprendimento? Come faccio ad avere la certezza che questa tecnologia aiuterà davvero i miei studenti?
Sono state condotte molte ricerche sui risultati dell’uso della sintesi vocale text-to-speech in ambito educativo. Ad esempio:
- Una ricerca condotta dall’Università di Barcellona dimostra chiaramente come la sintesi vocale text-to-speech sia uno strumento efficace per l’istruzione superiore.
- Uno studio del 2021 di Bruno et al. ha rilevato che l’istruzione diretta con strumenti di sintesi vocale text-to-speech ha migliorato i punteggi di comprensione di testi scritti tra gli studenti delle scuole superiori con disabilità intellettive e di sviluppo.
- Una meta-analisi del 2019 condotta da Wood, Moxley, Tighe e Wagner ha rilevato che la sintesi vocale text-to-speech ha migliorato i punteggi di comprensione della lettura per gli studenti con disabilità di lettura.
Per comprendere i processi neurologici coinvolti nell’apprendimento multi-modale con la sintesi vocale text-to-speech, oltre che per avere un’idea del valore dell’Universal Design for Learning – invitiamo a guardare la presentazione della dottoressa Trish Trifilo qui di seguito.
8. Ascoltare la versione audio un testo scritto non è un po’ come “barare”?
Quando si parla di tecnologia per l’istruzione e di strumenti di alfabetizzazione assistiva, spesso ci si chiede se l’uso della sintesi vocale text-to-speech possa essere considerato una vera e propria lettura. Come fanno gli studenti a imparare a leggere se un computer legge al posto loro? Cosa succede quando togliamo questo strumento?
Il problema non è solo la lettura, ma la quantità di tempo e di energia che la lettura richiede e la capacità del lettore di fare qualcosa con le informazioni acquisite. Come afferma Michelann Parr, specialista della sintesi vocale text-to-speech in ambito educativo:
“Vi garantisco che il nostro ruolo non prevede di togliere qualcosa, in particolar modo se questo promuove l’impegno e l’auto-efficacia degli studenti… Introducendo la sintesi vocale text-to-speech vi stupirete dei risultati che possono raggiungere i vostri studenti…”
Per ulteriori indicazioni sugli strumenti di sintesi vocale text-to-speech nell’educazione all’alfabetizzazione, ti invitiamo a leggere la nostra intervista con Michelann Parr dove avremo modo di approfondire tutte queste questioni.
9. In circolazione esistono molte soluzioni gratuite. Perché non usare una di queste opzioni?
Se da un lato è dimostrato che la sintesi vocale text-to-speech aiuta gli studenti di tutti i tipi, ci sono tuttavia alcune variabili che possono influenzare i risultati. Una delle principali variabili è la qualità della voce sintetica: Una scarsa qualità della voce porta a un’esperienza di apprendimento sgradevole, il che a sua volta porta a un minore utilizzo. Tutto questo, in ultima analisi, impedisce a studenti e insegnanti di sfruttare appieno i vantaggi della sintesi vocale text-to-speech. Le soluzioni di sintesi vocale text-to-speech gratuite non offrono voci della migliore qualità perché le aziende produttrici non si trovano nelle condizioni di reinvestire costantemente nel miglioramento tecnologico.
ReadSpeaker è una realtà in continuo miglioramento. I nostri modelli proprietari di apprendimento automatico ci consentono di creare voci sintetiche calde e realistiche che agli ascoltatori piace ascoltare. Effettivamente la ricerca suggerisce che le voci di alta qualità offerte dalla tecnologia di sintesi vocale text-to-speech di oggi possono produrre risultati di apprendimento migliori rispetto alle voci umane o ai vecchi motori di sintesi vocale text-to-speech.
Va poi aggiunto che gli strumenti di sintesi vocale text-to-speech di ReadSpeaker includono funzioni aggiuntive di alfabetizzazione, come quelle di cui abbiamo parlato nella domanda 2 di queste FAQ (evidenziazione della lettura, ridimensionamento del testo, maschere pagina e altro). Gli strumenti gratuiti di sintesi vocale text-to-speech tendono a essere scarni, e mettono a disposizione degli studenti un numero limitato di opzioni. Molti strumenti sono disponibili solo per determinati contenuti, mentre ReadSpeaker supporta testi on-line, documenti di Microsoft Office, file in formato PDF, formati di file ebook e molto altro.
Va tuttavia sottolineato che la sintesi vocale text-to-speech non deve necessariamente essere costosa per offrire agli utenti un’esperienza valida. La sintesi vocale text-to-speech è una tecnologia straordinariamente accessibile in termini di costi da fornire, sia a livello di singolo studente che di intero campus.
10. Deve essere difficile integrare questo aspetto nei contenuti. Come si fa a mantenere sempre tutti i contenuti abilitati al parlato?
La tecnologia di sintesi vocale text-to-speech, come la suite di strumenti di apprendimento audio potenziati di ReadSpeaker, è sorprendentemente facile non solo da implementare ma anche da utilizzare. Si tratta – al tempo stesso – di una soluzione conveniente in termini di costi. Sono finiti i tempi in cui si doveva scegliere tra voci robotiche o attori e studi di registrazione. Grazie all’output parlato prodotto dinamicamente e basato su cloud, i contenuti dei corsi sono immediatamente abilitati alla resa in formato parlato fin dal momento in cui vengono caricati. Ma non finisce qui: la tecnologia text-to-speech all’avanguardia fornisce voci realistiche di alta qualità.
Molto spesso le implementazioni sono dei semplici plug-in o delle righe di codice che richiedono poche ore di lavoro per essere implementate e mantenute. La maggior parte dei principali fornitori sistemi di gestione dell’apprendimento offre integrazioni specifiche che sarà sufficiente attivare.
Tutto questo consente alle istituzioni scolastiche di fornire in modo facile presentazioni bi-modali a tutti gli studenti. Con i corsi abilitati alla sintesi vocale text-to-speech, le lezioni, i test, i quiz, le valutazioni, i compiti di lettura e qualsiasi altro contenuto basato sul testo possono essere letti ad alta voce mentre gli studenti seguono il testo evidenziato. Il risultato? Gli studenti possono impegnarsi a fondo e fruire dei contenuti in più modi.
11. Non si tratta forse di un giocattolino tecnologico che dopo poco si rivela un abbaglio?
La sintesi vocale text-to-speech viene integrata nei contenuti di tutto il mondo, non solo nell’ambito dell’istruzione. Dai siti web governativi alle aziende, i leader di pensiero comprendono e sfruttano il potere della parola.
Gli istituti scolastici e gli editori innovativi fanno affidamento sulla tecnologia di sintesi vocale text-to-speech di ReadSpeaker per offrire modalità innovative di fruizione dei contenuti. Fra queste organizzazioni troviamo:
- Taylor & Francis
- Derby University
- Oxford University Press
- Erasmus University
- Learnosity
- Cengage
- MindTap
- Ebsco
Gli utenti di ReadSpeaker scoprono che la nostra tecnologia li aiuta ad attrarre e trattenere più studenti, migliorando al tempo stesso le esperienze e i risultati di apprendimento.
Entra anche tu nel nostro mondo. Predisporremo una demo gratuita e personalizzata sulle tue esigenze per farti vedere quanto è facile integrare l’audio nella tua istituzione.
Abbiamo risposto a tutte le tue domande? In caso contrario ti invitiamo a contattarci telefonicamente al numero +44 (0)7483 236 115 oppure a scriverci un’e-mail all’indirizzo contact@readspeaker.com.


